登录以参加训练计划
开始线段树之旅吧!
概念引入
概括地说,线段树是一种基于 分治思想 的 二叉树 结构,用于在区间上进行信息统计。与按照二进制进行区间划分的树状数组相比,线段树是一种 更加通用和灵活 的数据结构,功能比树状数组更强大:
- 线段树的每个结点都代表一个 区间/线段 (每个结点都维护对应子树的一些信息)。
- 线段树具有唯一的根结点,代表的区间是整个统计范围,如 \([1,N]\) 。
- 线段树的叶结点都代表一个长度为 \(1\) 的单位(元)区间 \([x,x]\) 。
- 对于 每个内部结点 \([l,r]\) ,它的左子结点是 \([l,mid]\) ,右子结点是 \([mid+1,r]\) ,其中 \(mid=(l+r)>>1\) 。
- 线段树是一棵二叉树,一个区间每次折一半往下分,包含 \(n\) 个元素的线段树,最多分 \(\log n\) 次就到达最低层。因此,当需要查找一个点或者区间的时候,顺着结点往下找, 最多 \(\log n\) 次就能找到 。
- 结点所表示的“线段”的值,可以是区间和、最值或者其他根据题目灵活定义的值。
比如说一个长度为 \(10\) 的线段,我们可以表示成这样(下图中 \([6,7]\) 下应为 \([6,6,],[7,7]\) ):

上面例子中,对应的线段树结构如下图所示:
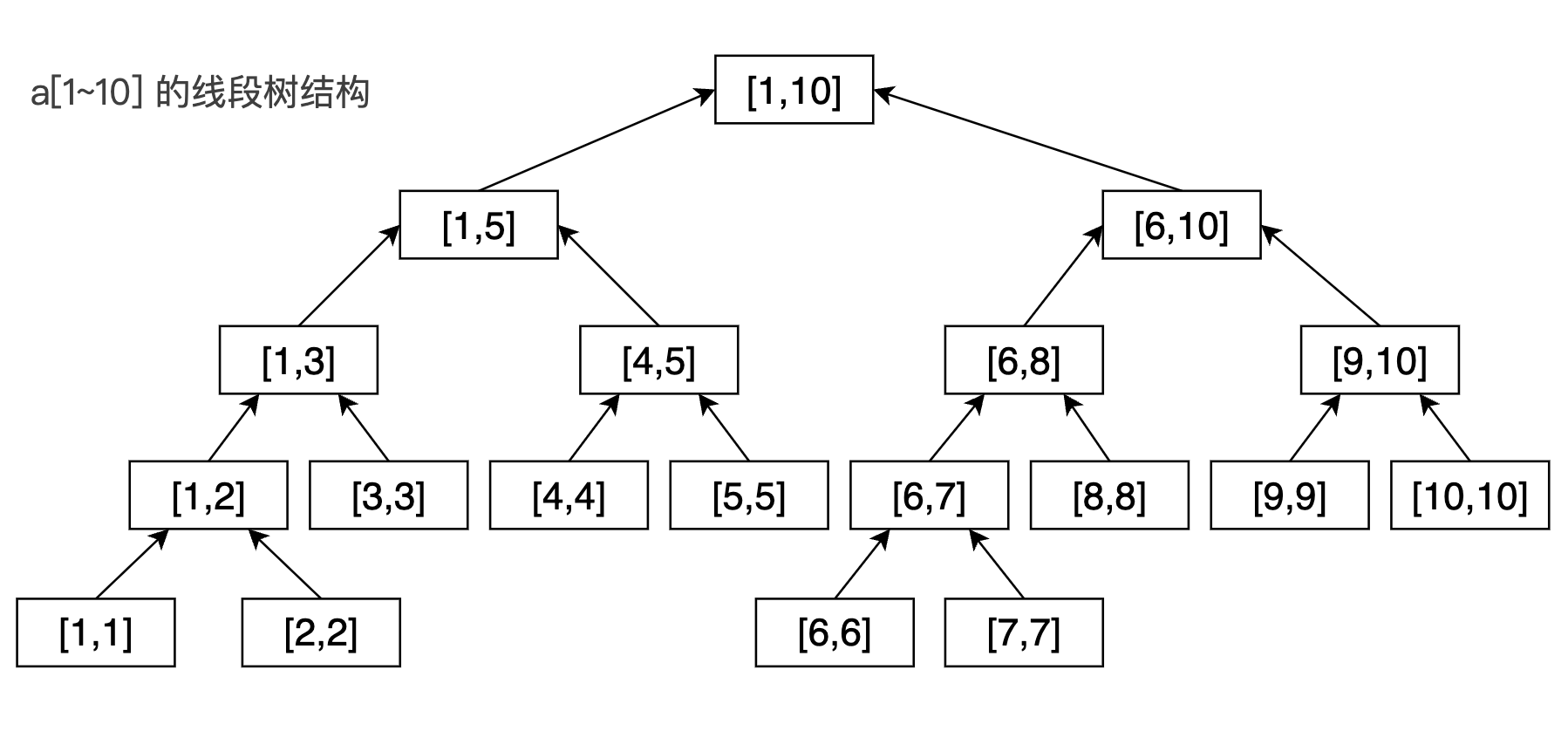
上图展示了一棵线段树。可以发现,除去树的最后一层,整棵线段树一定是一棵 完全二叉树 ,树的深度为 \(O(\log N)\) 。因此,我们可以按照完全二叉树的存储方法来保存结点间的关系:
- 根结点编号为 \(1\) 。
- 编号为 \(x\) 的结点的左子结点编号为 \(2x\) ,右子结点编号为 \(2x+1\) 。
当然,树的最后一层结点在数组中保存的位置不是连续的,直接空出数组中多余的位置即可。
在理想情况下, \(N\) 个叶结点的满二叉树有 \(N+N/2+ N/4+\cdots+2+1=2N-1\) 个结点。因为在上述存储方式下,最后还有一层可能产生了空余,所以保存线段树的数组长度要 不小于 \(4N\) 才能保证不会越界。
注意,这么做只是为了实现方便,实际上线段树存储还有其他更高效的实现方式,比如 ZKW 线段树,这里不做展开。
线段树的构建
线段树是除了最后一层之外,其他层都是满的一种树,这点和堆(完全二叉树)是一样的,因此可以使用(静态)一维数组来保存整棵树,虽然比较浪费空间,但是编码稍微简单一点。
下面给的代码使用静态分配的 \(tree[]\) 。父结点和子结点之间的访问非常简单,缺点是树的最后一层有大量结点被浪费。
// 定义根结点是tree[1],即编号为1的结点是根
// 第一种风格:定义二叉树数据结构
struct{
int l, r, data; // 用tree[i].data记录线段i的最值或区间和
} tree[N*4]; // 分配静态数组,开 4 倍大
// 第二种方法:直接用数组表示二叉树,更节省空间
int tree[N4]; // 用tree[i]记录线段i的最值或区间和
// 结点p是父结点, ls(p)是左儿子,rs(p)是右儿子
inline int ls(int x){ return x<<1; } // 左儿子 l,编号是 p2
inline int rs(int x){ return x<<1|1;} // 右儿子 r,编号是 p*2+1
在构建线段树时,我们考虑递归建树。设当前的根结点为 \(p\) ,如果根结点管辖的区间长度已经是 \(1\) ,则可以直接根据 \(a\) 数组上相应位置的值初始化该结点,否则我们将该区间从中点处分割为两个子区间,分别进入左右子结点递归建树。然后回溯的时候根据两个儿子的信息,更新父结点的信息即可。
下面这段代码建立了一棵线段树并在每个结点上保存了对应区间的最大值,可参考注释理解:
inline void push_up(int p){ // 从下往上传递区间值
// tree[p] = tree[p<<1] + tree[p<<1|1]; // 求区间和
tree[p] = max(tree[p<<1], tree[p<<1|1]); // 求区间最大值
}
void build(int p, int l, int r){ // 结点编号 p 指向区间[l, r]
if(l==r) { // 最底层的叶子,存叶子的值
tree[p]=a[l];
return;
}
int mid = (l + r) >> 1; // 分治:折半
build(p<<1, l, mid); // 递归左儿子
build(p<<1|1, mid+1, r); // 递归右儿子
push_up(p); // 从下往上传递区间值
}
// 建树的入口
build(1, 1, n);
注意:
- 建树的时间复杂度是 \(O(n)\) 的,因为它访问了线段树上每个结点各一次。
- 在线段树中,根结点是执行各种操作的入口。
- 回溯前,记得用两个子结点信息更新父结点信息。
- 值得一提的是,在线段树中,由两个子结点信息更新父结点信息的过程被称作
push_up操作。
线段树的单点修改
现在,假设我们要把 \(a[x]\) 加上 \(k\) 。
这个代码比较好写, 从根结点开始 ,看这个 \(x\) 是在左子树还是在右子树,递归查找,直到找到该叶子结点。需要注意的是在返回的时候, 最后不能漏掉 push_up 操作,来更新所有受到该叶子结点影响的父结点 。
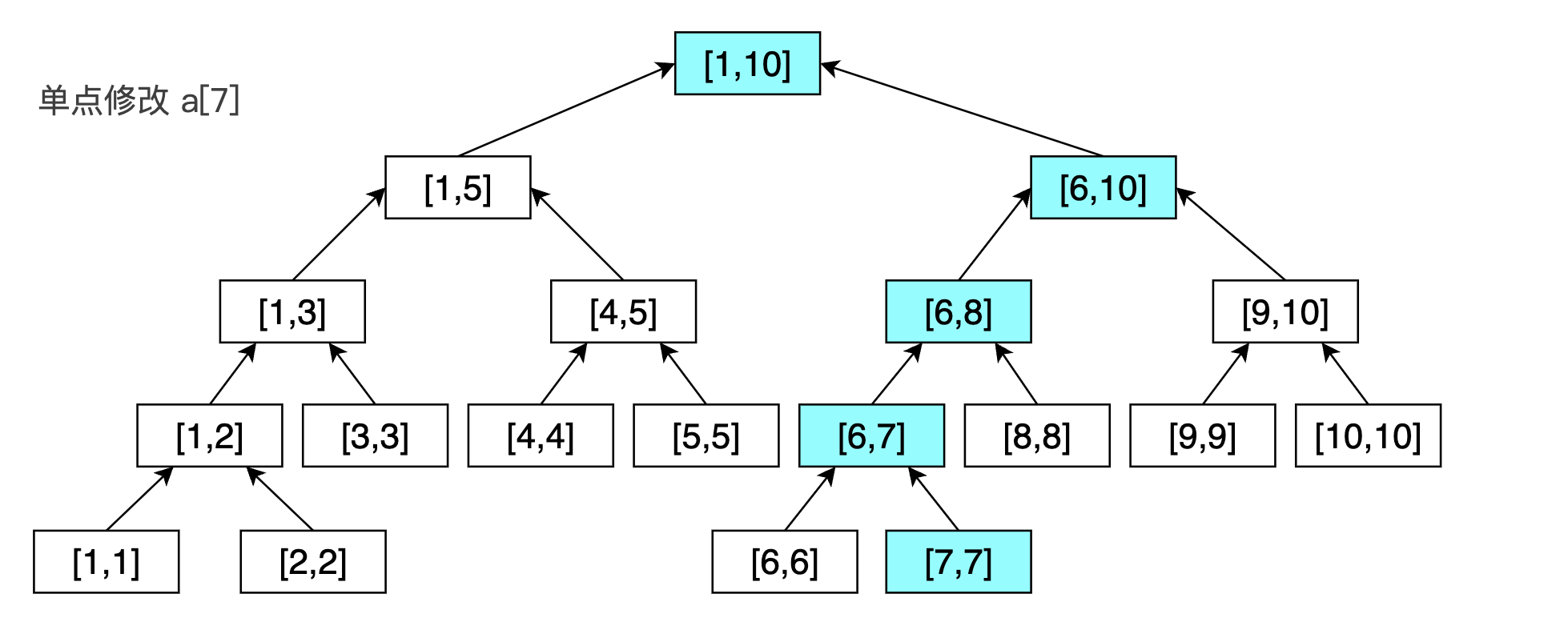
示例代码如下:
// 单点修改, x 位增加 k
void modify(int x, int k, int p, int l, int r) // l: p 对应区间的左端点, r: p 对应区间的右端点
{
if(l == r) { // 叶子结点
tree[p] += k;
return;
}
int mid = (l + r) >> 1;
if(x <= mid) modify(x, k, p*2, l, mid); // 在左子树
else modify(x, k, p*2+1, mid+1, r); // 在右子树
push_up(p); // 从下往上传递区间值
}
// 调用入口
modify(x, k, 1, 1, n);
可以看出,单点修改时,每层只会访问一个结点。因此,单点修改的时间复杂度为线段树的高度 \(O(\log n)\) 。
线段树的区间查询
现在,假设我们要查询区间 \([l,r]\) 上的信息(区间和、最大值、最小值等)。
由于我们的区间都是对半劈开的,假设我们要查询 \([l, r]\) ,我可以初始从代表 \([1, n]\) 的编号为 1 的结点进入。对于每个结点,我们会讨论:是否这个结点被 \([l, r]\) 完全覆盖,如果被完全覆盖,那么这个结点就是我们答案的一部分,直接返回该结点的值;如果未被完全覆盖,那么这个结点的两个儿子是否和 \([l,r]\) 有交集,如果有,则递归进入对应结点,如果没有,那么不递归进入这个结点。
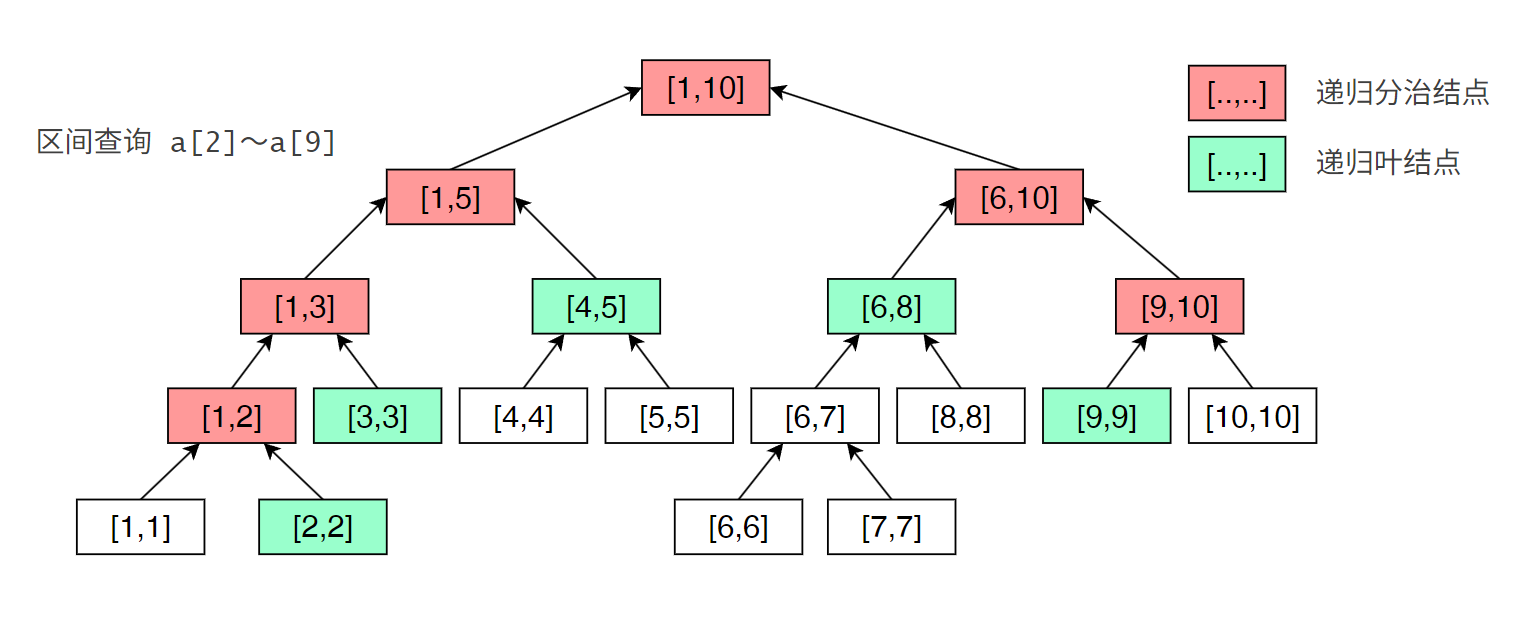
以求解区间和为例,实现的示例代码如下:
// 区间查询(区间和)
int query(int ql, int qr, int p, int l, int r)
{
if(ql <= l && r <= qr) return tree[p]; // 当前区间完全包含于查询的区间,直接返回该区间值
int ans = 0;
int mid = (l + r) >> 1;
if(ql <= mid) // 如果这个区间的左儿子和目标区间又交集,那么搜索左儿子
ans += query(ql, qr, p<<1, l, mid);
if(mid < qr) // 如果这个区间的右儿子和目标区间又交集,那么搜索右儿子
ans += query(ql, qr, p<<1|1, mid+1, r);
return ans;
}
// 求区间 [L,R] 的和的调用方式:query(L, R, 1, 1, n)
代码解释:
以查询区间 \([l, r]\) 的和为例,给出代码。查询递归到某个结点 \(p\) ( \(p\) 表示的区间是 \([pl, pr]\) )时,有 \(3\) 种情况:
- \([l,r]\) 完全覆盖了 \([pl, pr]\) ,即 \(l ≤ pl ≤ pr ≤ r\) ,直接返回结点 \(p\) 存储的值即可。
- \([l,r]\) 与 \([pl, pr]\) 不相交,即 \(l > pr\) 或者 \(r \lt pl\) ,退出( 这种情况在代码里不存在,因为初始区间 [1,n] 肯定包含目标区间 )。
- \([l,r]\) 与 \([pl, pr]\) 部分重叠,分别搜左右子结点。 \(l \lt pr\) ,继续递归左子结点,例如查询区间[4, 9],与第2个结点[1, 5]有重叠,因为4 < 5。R > pl,继续递归右子结点,例如[4, 9]与第3个结点[6, 10]有重叠,因为9 > 6。
由于树的高度是 \(O(\log n)\) 的,而每层最多访问 \(4\) 个结点,所以总访问结点数为 \(4 \times O(\log n) = O(\log n)\) 。所以,区间查询的时间复杂度也为 \(O(\log n)\) 。
思考:为什么线段树的区间查询每层最多访问 \(4\) 个结点?
提示:可以从询问的区间在线段树上的完整性出发去证明。
至此,线段树已经能够像 ST 算法一样,处理区间最值,也能像树状数组一样,处理区间上的单点修改和区间查询问题,且时间复杂度也为 \(O(\log n)\) 。
线段树的区间修改
懒惰标记的引入
现在我们考虑对区间 \([l, r]\) 上的每个数字都加上 \(k\) ,我们可以类似上面的单点修改,写一个区间修改的函数 update(L, R, l, r, k) 。如果当前区间 \([L,R]\) 的左子区间 \([L, Mid]\) 和 \([l, r]\) 有交集,我们就递归修改左子结点,如果 \([Mid+1,R]\) 和 \([l, r]\) 有交集,我也就递归修改右边的结点。最坏情况下,我们递归修改了所有的结点,时间复杂度为 \(O(n)\) ,这是不可接受的。
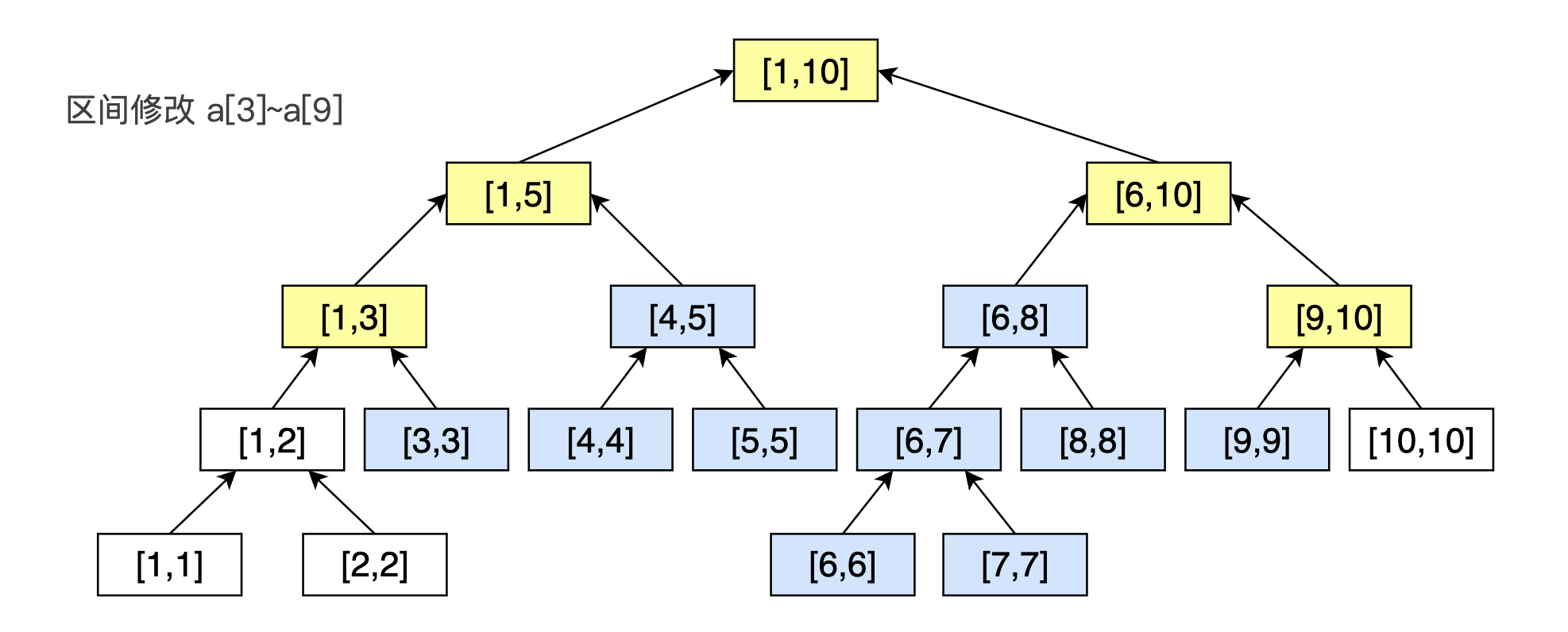
我们仔细观察我们需要修改的结点,会发现,其中有一部分是整个结点掌控的区间 \([L,R]\) 包含(在上图中用淡蓝色表示),另一部分只是单纯的有交集(在上图中用鹅黄色表示)。
我们发现,淡蓝色色的结点构成的都是一棵棵完整的子树。换句话说,这整个淡蓝色的结点的后继都要被完完全全地修改。
因此,我们想到了一个偷懒的方法,我们每次并不是完全把整棵树上所有受波及的点都给修改了,而是只修改到递归出现的淡蓝色的第一个点就停住,同时在停下的这个淡蓝色的结点放一个标记,意思是我偷懒了,我还没完全完成这次修改。这样,当我们再次递归到这个淡蓝色结点时,我们通过观察这个标记,就能了解到上次还未完成的情况,此时如果我还需要进一步往下递归,我就可以把这个标记下传,来得到它儿子结点的真实值了。
像这样,将修改信息停留在某些结点上,并给结点做上标记,这个标记就被称作延迟标记,俗称懒标记(英文名称为 lazy tag)。
这就有点像什么呢?有点像发工资。假设线段树的根结点是一个集团的最大的老板,每月到了发工资的时候,他就会把工资发给各个部门的经理(也就是下传标记时遇到的第一个淡蓝色结点),这些部门经理会假装把工资发到了每个员工的手里,但实际把工资攥在了自己手里。那如果上面要查账怎么办呢?没关系,账本上登记着“某年某月,给我部的员工发了 \(x\) 元工资”呢(这个账本就相当于偷懒标记)。同时,由于部门经理实际上收到了给该部门发的工资,他就在本部门收到的工资上登记了一个员工数量 × 工资的量,同时把本部门的收到的工资传递给上级,然后一级传一级一级传一级地向上传,每个部门收到的工资也都对得上数了(对应的是该区间的和在淡蓝色结点之上都是正确的)。实际上,只有谁的值是错的呢?只有部门经理之下的那些结点的值是错的。
那有一天,公司的监察部门过来查账了(对应一次区间查询,我们知道,区间查询可能查询到叶子结点也就是小员工头上),他有两种问法:
- “帮我查询一下你部门发的工资对不对”(对应的是需要查询的区间包含整个该部门的员工),这时候部门经理根本不慌,把账本呈上去,查账的人查完了就走了。
- “我要查一下你部门下面某个子部门的工资对不对”(对应的是需要查询的区间只包含了该部门的部分员工)。
这时候这个贪污了钱的部门经理可就慌了,他会怎么办呢?他会说好好好,我帮你查,然后赶紧把自己贪污的钱,发回给自己下面的两个子部门,让他们更新账本,然后再把检察官的任务传达给下面的两个子部门,直到什么时候结束呢?直到有一个部门发现,要查的是整个部门的账,那那个部门的经理就会把整个钱给收入囊中,然后更新账本,呈现上去。
运用懒惰标记进行区间加
我们还是从上面那个例子出发,我们如果采用懒惰标记的方法,我们进行区间加会触发的修改结点为下图淡蓝色的部分,而下图黄色的部分是在我们修改完淡蓝色的点后,通过已经修改的淡蓝色的结点就能向上回溯得到正确答案的结点,下图中的淡紫色部分是还被他的祖先欠有区间加信息的结点。

我们可以把懒惰标记的区间加法写成下面这样:
void addtag(int p, int l, int r, int d) { // 给结点p打tag标记,并更新tree
tag[p] += d; // 打上tag标记
tree[p] += d * (r - l + 1); // 计算新的tree
}
void push_down(int p, int l, int r) { //不能覆盖时,把tag传给子树
if (tag[p]) { //有tag标记,这是以前做区间修改时留下的
int mid = (l + r) >> 1;
addtag(p*2, l, mid, tag[p]); //把tag标记传给左子树
addtag(p*2+1, mid + 1, r, tag[p]); //把tag标记传给右子树
tag[p] = 0; //p自己的tag被传走了,归0
}
}
void modify(int ql, int qr, int p, int l, int r, int d) { //区间修改:把[L, R]内每个元素加上d
if (ql <= l && r <= qr) { // 完全覆盖,直接返回这个结点,它的子树不用再深入了
addtag(p, l, r, d); // 给结点p打tag标记,下一次区间修改到p这个结点时会用到
return;
}
push_down(p, l, r); // 如果不能覆盖,把tag传给子树
int mid = (l + r) >> 1;
if (ql <= mid) modify(ql, qr, p*2, l, mid, d); //递归左子树
if (qr > mid) modify(ql, qr, p*2+1, mid + 1, r, d); //递归右子树
push_up(p); //更新
}
可以注意到,区间加结束的点和区间查询非常类似,也是每层只有两个会继续递归的结点,所以加上懒惰标记之后,区间加操作的时间复杂度为 \(O(\log n)\) 。
我们再来考虑怎么实现查询操作,就类似于我上面讲的小故事,查到某个部门的头上,如果他欠有下面 部门的钱,我们就先把钱给还清,然后再放监察部门下去查。
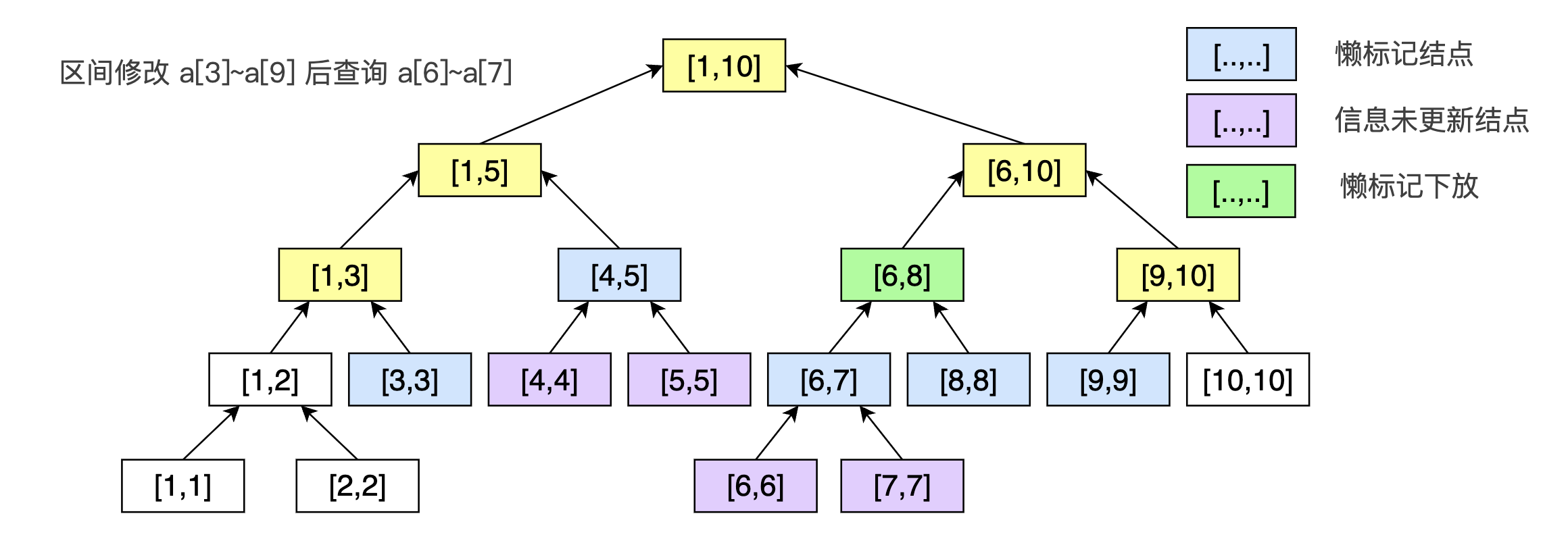
代码如下:
int query(int ql, int qr, int p, int l, int r) {
//查询区间[L,R];p是当前结点(线段)的编号,[pl,pr]是结点p表示的线段区间
if (ql <= l && r <= qr) return tree[p]; // 完全覆盖,直接返回
push_down(p, l, r); // 不能覆盖,把tag传给子树
int res = 0;
int mid = (l + r) >> 1;
if (ql <= mid) res += query(ql, qr, p*2, l, mid); // 左子结点有重叠
if (qr > mid) res += query(ql, qr, p*2+1, mid + 1, r); // 右子结点有重叠
return res;
}
可以注意到,加了懒标记之后,递归访问的结点数仍是每层只有两个会继续递归的结点,所以查询时间复杂度仍然是 \(O(\log n)\) 。
树状数组的区加区查模板(推公式)
#include<bits/stdc++.h>
#define ll long long
#define int ll
using namespace std;
int n,q,a[1000005],op,l,r,x;
ll c1[1000005],c2[1000005];
void add(int x,int k){
ll k1=k*x;
while(x<=n)c1[x]+=k,c2[x]+=k1,x+=(x&-x);
}
ll query(int x){
ll ans=0,xx=x+1;
while(x)ans+=xx*c1[x]-c2[x],x-=(x&-x);
return ans;
}
main(){
ios::sync_with_stdio(0);
cin.tie(0),cout.tie(0);
cin>>n>>q;
for(int i=1;i<=n;i++){
cin>>a[i];
add(i,a[i]-a[i-1]);
}
while(q--){
cin>>op>>l>>r;
if(op==1){
cin>>x;
add(l,x);add(r+1,-x);
}else{
cout<<query(r)-query(l-1)<<'\n';;
}
}
return 0;
}
- 参加人数
- 1
- 创建人
-
zap2727